发了篇新论文: Prefill-as-a-Service还蛮有意思的,可以看作大模型硬件架构未来的一个可能的发展方向吧。
大模型回答问题时主要分两个阶段。第一步叫 prefill:模型把用户输入全文读一遍,计算出后续生成要用的 KVCache。这一步主要吃算力,输入越长,计算压力越大。第二步叫 decode:模型根据 KVCache 一个 token 一个 token 往外生成答案。这一步主要吃显存带宽,因为每生成一个 token 都要频繁读取已有 KVCache。
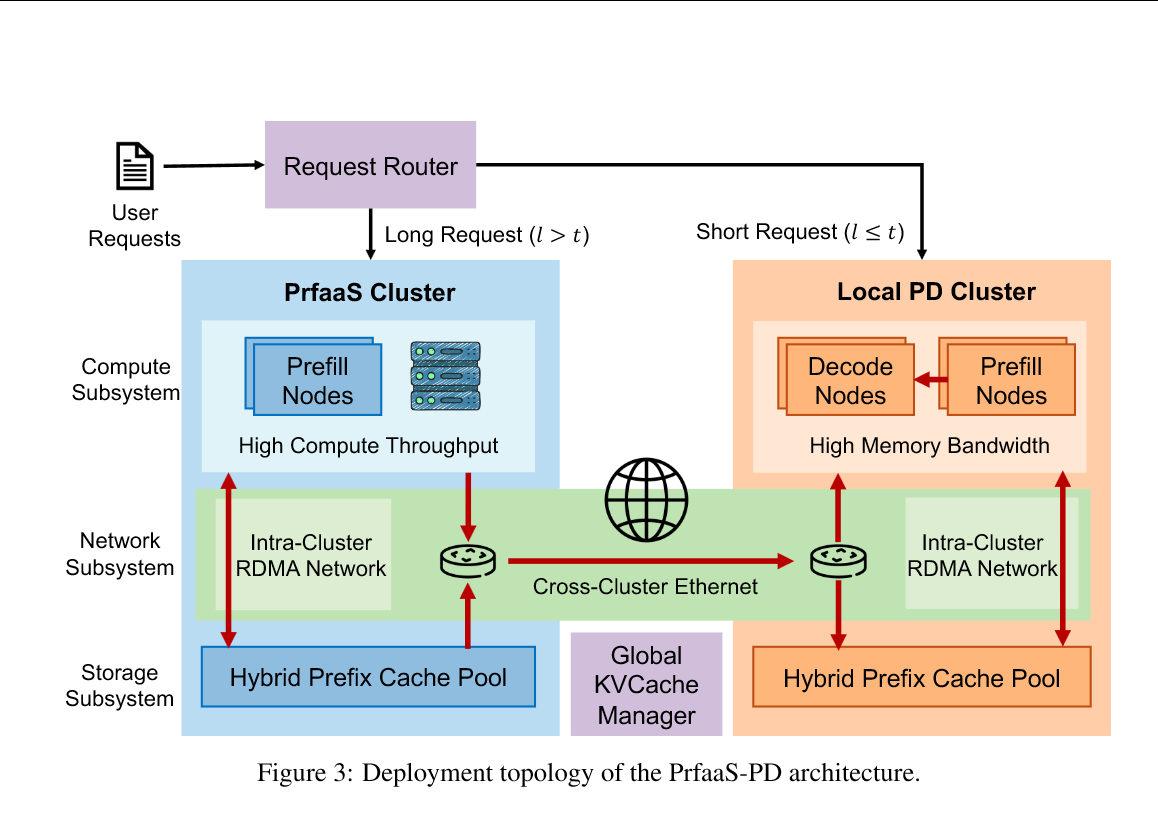
按理说,prefill 和 decode 适合放到不同类型的集群里优化:prefill 用高算力卡,decode 用高显存带宽卡。但传统 dense attention 模型产生的 KVCache 太大,跨网络传输成本很高,所以 prefill 和 decode 通常被限制在同一个高速网络集群里。
现在新的线性或混合注意力模型,比如 Kimi Linear 这类架构,大幅减少了 KVCache,使跨数据中心传输 KVCache 变得可行。那应该就有一种分开来各自优化的工程方案喽。
这篇论文介绍的 Prefill-as-a-Service,就是一种具体拆分方案:本地 PD 集群继续负责短请求和最终生成;远程 PrfaaS 集群专门负责长上下文 prefill;远程集群完成 prefill 后,把 KVCache 通过以太网传回本地 decode 集群。
这样做以后,具体收益有四个:1. 吞吐更高长请求的 prefill 很重,放到专门的 PrfaaS 集群处理后,本地集群腾出更多资源做 decode。论文案例里,PrfaaS-PD 的吞吐达到 3.24 req/s,相比同构 PD 的 2.11 req/s 提升 54%。2. 长请求首 token 延迟更低用户等待第一个 token 的时间主要受 prefill 影响。长上下文请求被送到更快的 prefill 集群后,排队和计算时间都下降。论文里 P90 TTFT 从 9.73 秒降到 3.51 秒,下降 64%。3. 硬件采购和部署更灵活Prefill 可以用高算力卡,decode 可以用高显存带宽卡。二者可以在不同数据中心、不同机型、不同供应池里部署,避免强行把异构硬件塞进同一个 RDMA 高速网络集群。4. 弹性更好请求结构变化时,可以调节“多少长请求外包”“本地多少机器做 prefill、多少机器做 decode”。这比固定比例的异构集群更容易适应流量波动。
论文地址:arxiv.org/pdf/2604.15039v1html版:arxiv.org/html/2604.15039v1
AI创造营