
本文仅在今日头条发布,谢绝转载。
英伟达的黄仁勋非常非常沮丧!因为中国居然拒绝了英伟达的H200芯片,没有帮助它们去库存!更关键的是,伴随着国产算力越来越强,这批库存芯片大概率要吃灰了!!!
在2026年这个历史性的算力转折点,我们正在见证计算架构从“单体服务器”向“超节点(Supernode/SuperPoD)”整机柜形态的剧烈演进。
超节点作为整机柜级一体化紧耦合算力系统,已成为AI大模型训练与超算中心建设的核心基础设施。2026年是国产超节点方案从概念验证走向量产落地的关键转折年——华为Atlas A3900 SuperPoD、阿里磐火、中科曙光ScaleX640等厂商自研方案密集推出,在集成密度、通信速率和计算能力等多项核心指标上已跻身世界一流水平。
第一章——国产算力崛起
在2026年这个历史性的算力转折点,我们正在见证计算架构从“单体服务器”向“超节点(Supernode/SuperPoD)”整机柜形态的剧烈演进。
超节点作为整机柜级一体化紧耦合算力系统,已成为AI大模型训练与超算中心建设的核心基础设施。2026年是国产超节点方案从概念验证走向量产落地的关键转折年——华为Atlas A3900 SuperPoD、阿里磐火、中科曙光ScaleX640等厂商自研方案密集推出,在集成密度、通信速率和计算能力等多项核心指标上已跻身世界一流水平。
行业基本面正在发生深刻变化。从技术路径看,以太网凭借开放生态、低成本、多厂商兼容的核心优势,正加速成为AI算力Scale Up的主流互联协议,成为打破英伟达NVLink生态垄断的最优解。从竞争格局看,国产交换芯片预计2026年规模化出货,国产交换芯片正在改写由博通等海外巨头长期垄断的高端市场格局。
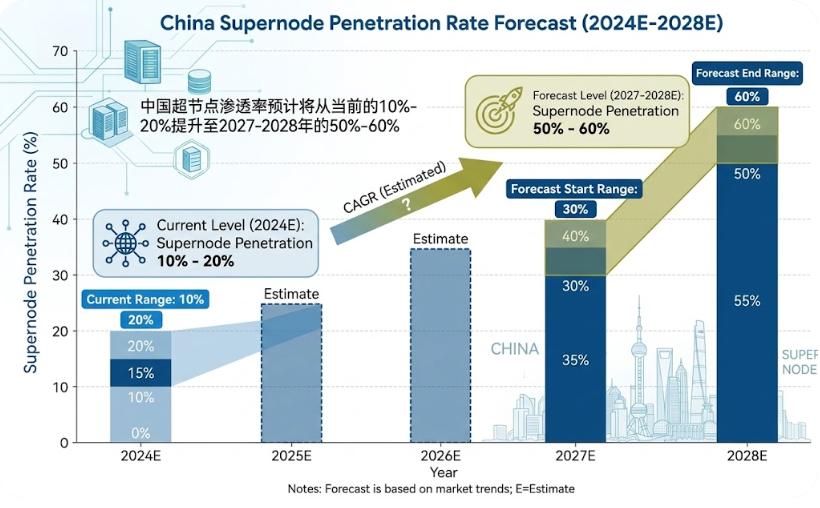
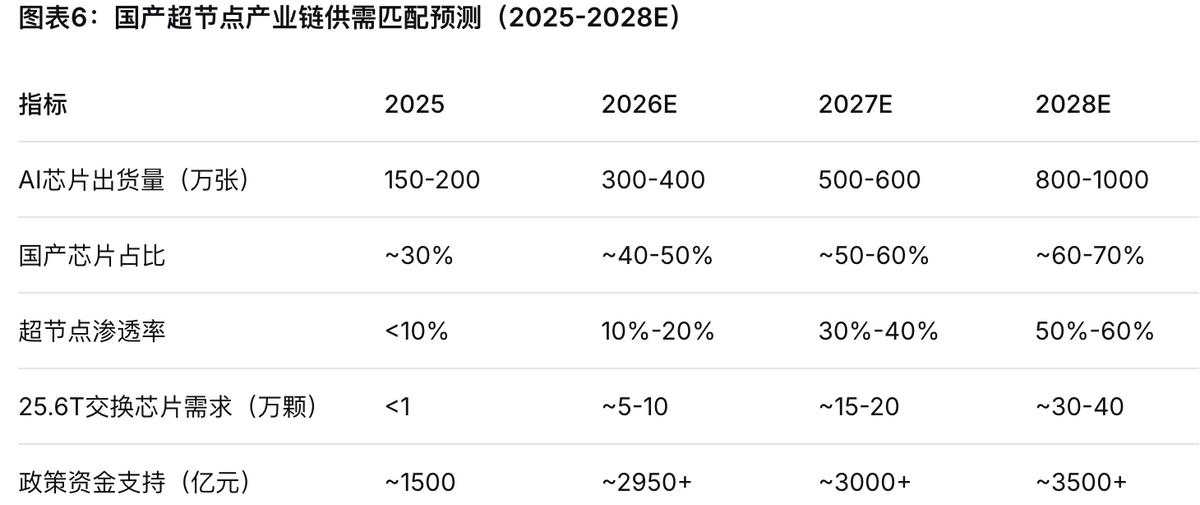
从产业节奏看,超节点渗透率预计将从当前的10%-20%提升至2027-2028年的50%-60%,产业拐点即将到来。国产算力芯片的使用比例有望在未来超越海外芯片,自主可控的算力基础设施建设正在进入加速通道。综合供给端产能爬坡节奏与需求端政策催化力度,我们认为2026-2028年是国产超节点产业链格局成型和龙头份额集中的关键窗口期。
什么是超节点?
超节点是面向大模型训练与推理设计的新一代整机柜级一体化AI算力基础设施,它将数十到数百颗GPU/NPU在物理与逻辑层面深度紧耦合,通过自研高速互联协议、全局统一内存和整机柜级供配电与散热体系,让多机柜、上万颗芯片组成的集群在使用上如同一台巨型超级计算机,是当前高密度AI算力的主流架构形态。
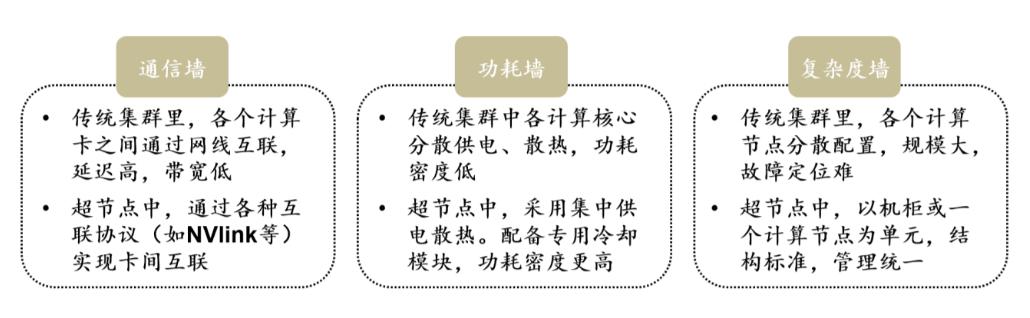
引入超节点是为了解决传统服务器集群在大模型训练中面临的通信墙、功耗墙、复杂度墙三大瓶颈:传统以太网与PCIe组网时延高、带宽不足,导致万卡集群算力利用率大幅下降;高密度AI芯片功耗飙升,风冷无法满足散热需求;松散堆叠的服务器部署复杂、故障点多、调度效率低。超节点通过柜内紧耦合、原生液冷、集中供电与统一管理,大幅提升通信效率、降低能耗、简化部署,让万亿参数模型训练成为可能。
2024-2025年:国产超节点方案密集发布
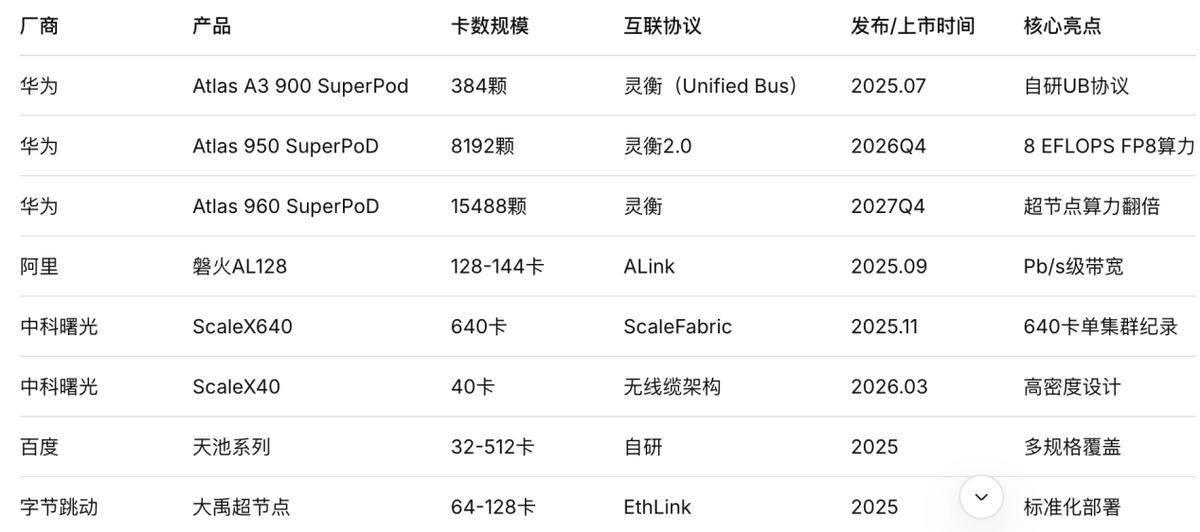
2024年11月:腾讯联合中国信通院发布ETH-X超节点方案,单机柜支持64颗GPU,通过以太网RoCE协议实现机柜内互联;
2025年7月:华为推出Atlas A3900 SuperPod,最大支持384颗昇腾910 NPU与自研灵衡(Unified Bus)协议;
2025年9月:阿里发布磐火AL128超节点,以128-144卡高密配置、自研ALink协议实现Pb/s级带宽;
2025年11月:中科曙光ScaleX640以640卡规模刷新纪录,搭载海光DCU算力核心;百度天池系列覆盖32-512卡多规格并搭载自研互联协议;字节跳动大禹超节点以64-128卡配置、自研EthLink协议实现标准化部署。
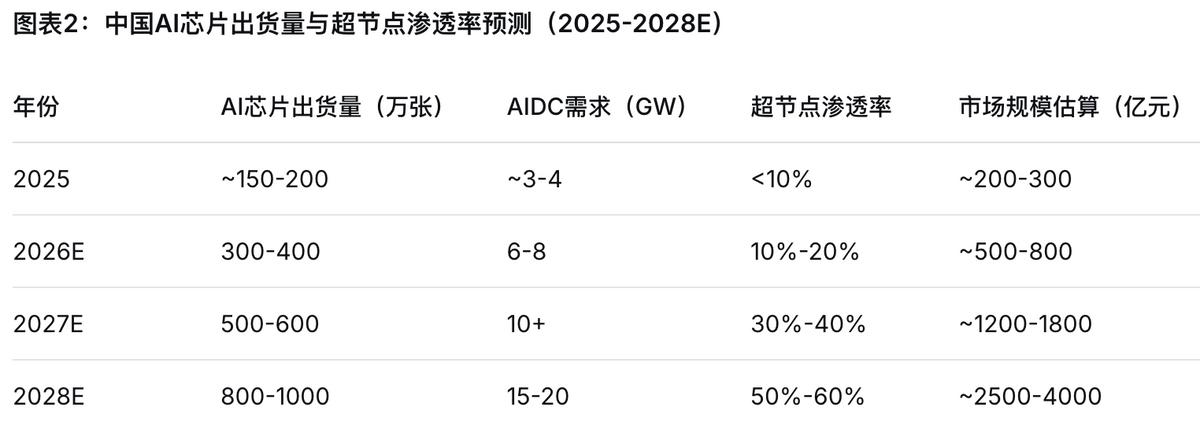
从芯片端看,2026年国内预计有300-400万张AI芯片(含受限供应的H200及国产算力卡),按1千瓦芯片算对应6-8GW AIDC需求;2027年500-600万张卡则对应超10GW需求;2026-2027年总需求合计15-16GW。
超节点渗透率的快速提升意味着国产算力芯片的份额正在加速扩张。曾有国产算力芯片厂商高管预测,国产算力芯片的使用比例将会超过海外芯片,产业拐点将在2027-2028年发生。
第二章——重构AI网络
在超节点架构中,GPU之间的高速互联协议是决定集群通信效率和算力利用率的核心技术。Scale Up互联(纵向扩展网络)负责单个超节点内数十到数百颗GPU的直接数据交换,其带宽、时延和生态兼容性直接决定了超节点的整体性能。
当前国际格局是英伟达NVLink封闭生态 vs 以太网开放生态。
英伟达依托NVLink构建了深度的技术壁垒。新一代NVLink5交换机实现14.4TB/s无阻塞交换容量,单Pod可支持最多576个GPU互联;2025年5月推出的NVLink融合开放方案进一步将单端口带宽提升至900GB/s,但底层技术的封闭性仍限制了多厂商GPU的深度协同。
以太网开放生态:打破NVLink垄断的最优解
以AMD主导的UALink、博通推出的SUE为代表基于以太网的开源协议,正成为打破NVLink垄断的核心力量。UALink 200G 1.0规范于2025年4月公开发布,支持200G per lane信令、x1/x2/x4链路配置,单Pod可扩展至1024个加速器,具备确定性性能。博通SUE则深度绑定以太网技术生态,2025年6月更新的规范支持1/2/4端口灵活配置,可适配全交换、网状拓扑等大规模组网场景,通过将GPU专有事务封装在以太网帧内复用现有协议逻辑,大幅降低部署成本。
以太网成为Scale Up主流协议的核心优势体现在两个层面:
开放生态重构竞争格局:自2023年起以太网联盟UEC成立,2025年OCP全球峰会上,英伟达也加入与AMD、英特尔、博通等巨头的合作,联合成立ESUN联盟推动以太网适配Scale Up需求。以太网兼容现有数据中心基础设施,适配多厂商XPU设备协同,规避供应商锁定风险,同时降低部署成本。
技术策略补足延迟短板:以太网原生存在协议层过多、通信低效导致的延迟劣势,但通过“在网计算”和“计算与通信重叠”两大技术策略,已形成有效解决方案。博通Tomahawk Ultra交换机引入在网计算能力,将以太网交换机时延优化至250ns级别,大幅缩小了与PCIe交换机115ns时延的差距。

围绕自主可控、适配国产算力生态,国内形成了三条技术路线:
路线一:自主可控专用系统总线
华为灵衡(Unified Bus) :于2019年开始研究,2025年9月发布并开放灵衡2.0技术规范。单Lane速率达118Gbps,支持TB/s级带宽互联;物理层线性直驱光技术实现<10ns端口时延;平等协同实现超节点全组件互联,无需CPU中转;支持多级UB Switch扩展及UBoE与以太网融合组网,适配超大规模集群扩张需求。华为已宣布开放灵衡2.0规范,邀请产业界伙伴基于灵衡研发相关产品,共建开放生态。
海光HSL(High-performance Scalable Link) :于2025年9月推出,12月发布1.0规范。HSL协议涵盖完整总线协议栈、IP参考设计及指令集,海光已联合10余家厂商共建生态。全层级互联覆盖芯片、板卡、服务器等任意层级,支持全局地址空间与缓存一致性。当前起步速率112G,后续将升级至240G,带宽较32G PCIe提升8倍,时延较PCIe降低约一半。海光信息深度参与《超节点技术体系白皮书》编制,重点承担了全对等互联、HSL总线型协议等相关技术模块的研究与撰写,为超节点技术体系落地提供了关键的国产化技术支撑。
路线二:以太网优化
字节跳动EthLink:具备完整拓扑感知能力,覆盖服务器内及跨服务器GPU互联场景,单协议支持1-4个以太网接口,可通过低时延以太网交换实现最大1024个GPU节点的Scale Up组网。
腾讯Eth-X:针对GPU-Switch互通、GPU-GPU访存两类核心需求分层设计,GPU-GPU侧支持直接拷贝、DMA、统一编址等语义,GPU-Switch侧基于以太网交换融合DMA、ETH、MEM能力。
路线三:开放基础设施架构
中国移动OISA:定义物理层、数据链路层、事务层标准,具备统一报文格式、多语义融合、多层次流控等特性。
2026年是供需关系转变的关键年份:供给端国产芯片产能快速爬坡,25.6T交换芯片规模化出货;需求端阿里、字节、腾讯等互联网大厂超算节点规划明确,政策资金加速到位。2026-2028年超节点渗透率有望从当前的10%-20%快速提升至50%-60%,供需两旺的格局将推动国产超节点产业链进入加速发展期。
第三章——产业链核心价值
国产超节点产业的演进路径可划分为四个核心阶段:
阶段一(2024-2025):技术验证与方案发布期。 国产超节点方案密集发布,完成从概念到产品的技术验证。华为、阿里、中科曙光、百度、字节跳动等厂商纷纷推出自研方案,在集成密度、通信速率等关键指标上接近国际一流水平。当前已基本完成。
阶段二(2026-2027):量产元年与渗透率加速期。 国产超节点方案进入量产落地阶段,超节点渗透率从当前10%-20%快速提升至30%-40%。盛科通信25.6T交换芯片规模化出货,华为昇腾950系列芯片量产,国产算力芯片使用比例加速提升。当前正处于这一阶段的关键起点。
阶段三(2027-2029):规模扩张与格局固化期。 国产超节点渗透率提升至50%-60%以上,华为昇腾960系列、海光DCU迭代产品大规模落地。产业链价值分配趋于清晰,龙头厂商市场份额持续集中。
阶段四(2029后):生态成熟与全球化竞争期。 国产算力生态全面成熟,国产芯片在全球AI算力市场中占据重要地位,自主可控的算力基础设施成为国家战略资产。
核心结论如下——
结论一:超节点是AI算力基建的核心形态,国产超节点方案正在加速追赶国际一流水平。 华为Atlas 950 SuperPoD在卡数规模、互联带宽、算力密度等指标上已实现对英伟达NVL576的超前布局,国产厂商在超节点赛道已形成百花齐放、加速追赶的良好态势。
结论二:以太网开放生态正在打破英伟达NVLink的长期垄断,成为Scale Up互联的主流路径。 以太网凭借开放生态、低成本、多厂商兼容的核心优势,正加速成为AI算力Scale Up的主流互联协议。华为灵衡、海光HSL等国产自研协议的开放,进一步丰富了国产算力的技术选择。
结论三:国产交换芯片正从“破局者”向“主导者”转变,盛科通信是核心受益标的。 盛科通信25.6T芯片2026年规模化出货,在国内市场占据绝对优势地位,在Scale-up市场份额超90%、Scale-out市场保底20%。阿里、字节、腾讯2026年合计交换芯片需求超10万颗,国产化替代空间广阔。
结论四:2026-2028年是国产超节点产业链投资的关键窗口期。 超节点渗透率预计从10%-20%提升至50%-60%,芯片、交换芯片、互联协议等核心环节均处于国产化加速期。综合政策催化力度、供给端产能爬坡节奏与需求端规模化落地进度,超节点产业将在未来2-3年迎来价值重估。